So führen Sie Datenbankabfragen zur Automatisierung durch
Um den Grad der Automatisierung zu erhöhen, lassen sich zur Auftragsverteilung, Auslastung, Bearbeitungsstand, Stückzahlen und Rüstzustand in der PPS-Datenbank Abfragen mit entsprechenden Kriterien durchführen.
Dazu können Sie Select-Abfragen an die PPS-Datenbank richten.
In den nachfolgenden Beispielen, ist der an d.uid zugewiesene Wert die UID der Maschine.
Um die UID ausgehend vom Maschinennetzwerknamen zu ermitteln, können Sie Konvertierungsfunktionen benutzen oder die Funktion skrpps_02.skr_get_mc_list verwenden.
Siehe: Verschiedene Hilfsfunktionen für weitere performanceoptimierte Optionen.
Beispiel:
SELECT "BO_GUID" from skrpps_02.skr_get_mc_list('skr') where "MC_NAME"='McNetworkName';
Die Abfrage liefert Ihnen die UID der Maschine, wenn Sie für McNetworkName den Netzwerknamen Ihrer Maschinen einsetzen.
Aus der PPS-Datenbank können Sie ermitteln:
- Anzahl der Aufträge
- noch zu erledigende Aufträge, die der Maschinen schon zugeteilt wurden (APPROVED)
- gerade in Erledigung (IN_PROGRESS)
- für die gerade eine Aktivität (Drucken) läuft (IN_ACTIVITY)
- SQL Abfrage:
SELECT count(t) FROM ticket t JOIN device d on t.device_id = d.id WHERE t.state in ('APPROVED', 'IN_PROGRESS', 'IN_ACTIVITY') AND d.uid='56665454' - Hinweis:
Wenn Siecount(t)durch*ersetzen, erhalten Sie eine Tabelle mit Informationen zu den Tickets und der Maschine.
So können Sie z.B. die Namen der Tickets oder den Erledigungsstand auf der Maschine ermitteln. - Falls Sie nur wissen wollen, wie viele Tickets schon in ToDo sind.
Ersetzen Sie dazu …t.state in (…)durch …t.state='APPROVED'. - Statt
d.uid='56665454'können Sie auchd.name='McNetworkName'oderd.skrmachineid=1480329483einsetzen, um das Ermitteln der UID zu vermeiden.
Beachten Sie aber, dass nur die UID eindeutig ist. Der Netzwerkname kann sich ändern. Wenn Sie die Maschine erneut ins SKR aufnehmen, ändert sich auch die SKRID. - Zeitdauer, bis die Maschine alle Aufträge abgearbeitet hat.
Es lässt sich ermitteln, wie lange die Maschine mit den freigegebenen Aufträgen beschäftigt sein wird. Basis für die Berechnung ist die Zeit pro Teil, die im Auftrag vorgegeben wurde, und die konfigurierte Schicht-Effizienz, sowie, falls genutzt, der Wert, der in Tag STOLL:PRODUCTION_EFFICIENCY gesetzt wurde. Bei laufenden Aufträgen mit mehreren Teilen wird eine Hochrechnung auf das Ende durchgeführt. Und mit jedem Teil nähert sich die Hochrechnung an die tatsächliche Endzeit an.
SQL Abfrage:SELECT max(t.endDate) FROM Ticket t JOIN Device d on t.device_id = d.id WHERE t.state in ('APPROVED','IN_PROGRESS', 'IN_ACTIVITY') AND d.uid='56665454' - Wann ein Auftrag beendet wurde?
Für die Abfrage über die pps-Datenbank, müssen Sie Ihren Auftragsnamen (ordernumber) zur Identifikation des Auftrags kennen (a).
Empfehlung: Im Auftrag die PRODUCTION_ID (productionid) setzen und darüber den Auftrag identifizieren (b).
Die Abfragen liefern die Information, wann ein Auftrag abgeschlossen wurde. -
(a) SELECT aggregatedenddate FROM orders o WHERE state='DONE' AND ordernumber='ADF530-32W_REFLEX_30_08-20220503-093844' -
(b) SELECT aggregatedenddate FROM orders o WHERE state='DONE' AND productionid='20220503-093844' - Wann ein Ticket beendet wurde?
Falls ein Auftrag aufgesplittet ist, und Sie wollen ermitteln, wann ein Ticket beendet wurde, müssen Sie eine andere Abfrage über die pps-Datenbank ausführen. Sie sollten auch hier den Auftragsnamen (ordernumber) zur Identifikation des Auftrags kennen (a). Empfehlung: Im Auftrag die PRODUCTION_ID (productionid) setzen und darüber den Auftrag identifizieren (b).
Die Abfragen liefern die Information, wann das letzte Ticket aus einem Split-Auftrag abgeschlossen wurde. -
(a) SELECT max(t.finished) FROM ticket t JOIN orders o on t.ppsproductionuid=o.productionuid WHERE t.state in ('DONE') AND o.ordernumber='ADF530-32W_REFLEX_30_08-20220503-093844' -
(b) SELECT max(t.finished) FROM ticket t JOIN orders o on t.ppsproductionuid=o.productionuid WHERE t.state in ('DONE') AND productionid='20220503-093844' - Welche Maschine das letzte Teil gestrickt hat?
- Mit Umstellung auf die Postgres Datenbank ab Version 14 sind die PPS und SKR Datenbank zusammengelegt, um Aufrufe über die Datenbanken hinweg zu vereinfachen.
-
(a) SELECT max(t.finished), skrpps_02.agg_at_min (extract(epoch from t.finished)::bigint, d.name) FROM ticket t JOIN orders o on t.ppsproductionuid=o.productionuid JOIN device d on d.id=t.device_id WHERE t.state in ('DONE') AND o.ordernumber='ADF530-32W_REFLEX_30_08-20220503-093844' - Wann eine bestimmte Maschine das letzte Ticket von einem Split-Auftrag (ordernumber) beendet hat?
- Die Maschine wird über ihre UID (d.uid) gefiltert.
Andere Indikationen wie Netzwerkname (d.name), MAC (d.macaddress) oder IP (d.ipaddress) sind auch möglich. -
SELECT max(t.finished) FROM ticket t JOIN orders o on t.ppsproductionuid=o.productionuid JOIN device d on d.id=t.device_id WHERE t.state in ('DONE') AND d.uid='56665454' AND ordernumber='ADF530-32W_REFLEX_30_08-20220503-093844' - Wie viele Teile produziert wurden?
- Bei bekanntem Auftragsnamen
-
SELECT sum(t.executionsdone) FROM ticket t JOIN orders o on t.ppsproductionuid=o.productionuid WHERE ordernumber='ADF530-32W_REFLEX_30_08-20220503-093844' - Bei bekannter PRODUCTION_ID, die im Ticket angegeben wurde
-
SELECT sum(t.executionsdone) FROM ticket t JOIN orders o on t.ppsproductionuid=o.productionuid WHERE productionid= '20220503-093844' - Ab dem Planungsstadium:
- Wann ein Auftrag startet und endet?
- Wie der Auftragsstatus ist?
- Wie viele Stücke produziert sind?
- Welche Maschinen beteiligt sind?
- Bei bekannter ProductionID
-
SELECT o.aggregatedstartdate, o.aggregatedenddate, o.state, sum(t.executionsdone) OVER (PARTITION BY o.aggregatedstartdate) AS aggregatedexecutionsdone, d.uid -
FROM public.orders o -
JOIN public.ticket t on o.productionuid=t.ppsproductionuid -
JOIN public.device d on t.device_id=d.id -
WHERE o.productionid='20220503-093844' AND o.state in ('PLANNED', 'APPROVED','IN_PROGRESS', 'IN_ACTIVITY', 'DONE'); - Weitere Daten abfragen durch Anfügen an d.uid:
-
,o.id, o.ordernumber, o.articlenumber, o.productionid, o.productionsub1id, o.productionsub2id, o.customerid, o.totalnumberofexecutions, o.orderdescription, o.patternfilename, o.patternsubdirectory, o.productionuid, o.originalnumberofexecutions, o.state, o.delay - Rüstzustand der Maschine
- Über das PPS lässt sich ein Rüstauftrag auf die Maschinen verteilen.
Die Ticket-Vorlage AutoProduction enthält bereits zwei Felder und zur Eingabe dafür.
Im Ticket kann ein Tag verwendet werden, das einen Rüstzustand definiert. Es können mehrere Rüstzustände definiert werden, wenn der Rüstzustand für mehrere Gestricke geeignet ist. Der Rüstzustand kann auch mit einem Strickticket gesetzt werden, wenn keine Rüstaufträge verwendet werden sollen. - Der Rüstzustand wird über diesen Tag festgelegt:
<STOLL:REQUIRED_SETUP_LEVELS>
<STOLL:SETUP Level="F46r548"/>
<STOLL:SETUP Level="F15r773"/>
...
</STOLL:REQUIRED_SETUP_LEVELS> - Wenn so ein Ticket an der Maschine in die Bearbeitung gebracht oder erledigt ist, lässt sich nach Maschinen mit z.B. diesem Rüstzustand
F46r548suchen.
SQL-Abfrage der pps DB:SELECT d.name, d.uid, l.value from loopthroughitementry l JOIN orders_loopthroughitementry ol on l.id = ol.loopthroughitems_id JOIN Orders o ON o.id = ol.orders_id
JOIN Ticket t on t.order_id = o.id
JOIN Device d on t.device_id = d.id where
key='REQUIRED_SETUP_LEVELS' and l.value like '%"F46r548"%';
Abfrage über eine Batch-Datei, wann eine Maschine mit allen Tickets fertig ist
Im nachfolgenden Beispiel wird die Zeit abgefragt, wann die Maschine mit einer bestimmten UID mit allen Tickets fertig ist.
Kopieren Sie den Code in eine Batch Datei, setzen Sie die Variable Machine_UID auf einen Wert von einer Ihrer Maschinen und führen Sie den Code mit Administratorrechten aus. In der Variable DONE_TIME erhalten Sie das Ergebnis der Abfrage.
@echo off
setlocal enabledelayedexpansion
set "PgLatestRootPath=C:\Program Files\Stoll\skr3\PostgreSql\9.5.5-1\bin"
set "PgRootPath=!PgLatestRootPath!"
if not exist "!PgRootPath!" Set "PgRootPath=C:\Program Files\Stoll\skr3\PostgreSql\9.5.3-1\bin"
set "Machine_UID=56665454"
call :GetDoneTime !Machine_UID! DONE_TIME
echo DONE_TIME=!DONE_TIME!, ErrorLevel=!ErrorLevel!
goto :EOF
:GetDoneTime
call :UndefErrorLevel
set "MC_UID=%~1"
set "ReturnDoneTimeValueRef=%~2"
set "DataVal=NULL"
set "PGPASSWORD=ppsfrontend"
set "PGCLIENTENCODING=utf-8"
set pd_SelCmd=SELECT max(t.endDate) FROM Ticket t JOIN Device d on t.device_id = d.id WHERE t.state in ('APPROVED','IN_PROGRESS', 'IN_ACTIVITY') AND d.uid='!MC_UID!';
set pg_SelCall="!PgRootPath!\psql" -U ppsfrontend -h localhost -d pps
set pg_cmd="echo !pd_SelCmd! | !pg_SelCall! || echo/ & echo/ & call echo NULL NULL %%^^^errorlevel%%"
set "pg_cmd=!pg_cmd:)=^)!"
REM Execute PG command and split up table at | and space. Resulting DataValue obtained from second column.
REM Check for errors of call
for /f "skip=2 tokens=1,2,3" %%i in ('!pg_cmd!') do (
REM Get value in first and second parameter from split - which is from third row
set "DataVal=%%i %%j"
REM If error happend, report it. Error code is obtained in 3rd parameter.
if "!DataVal!"=="NULL NULL" (
echo ## Postgres DB operation failed with ERROR: %%~k
set "DataVal=NULL"
) else (
REM Check if not valid
if "!DataVal:~0,1!"=="(" set "DataVal=NULL"
)
goto GotDoneTime
)
:GotDoneTime
if not '!ReturnDoneTimeValueRef!'=='' set "!ReturnDoneTimeValueRef!=!DataVal!"
if "!DataVal!"=="NULL" set "ERRORLEVEL=1" & exit /b 1
exit /b 0
:UndefErrorLevel
REM Undefine ERRORLEVEL, otherwise !ERRORLEVEL! keeps last set value. The ERRORLEVEL system value is not the same as !ERRORLEVEL!
set "ERRORLEVEL="
exit /b 0
Beispielausgabe:
D:\PPS\PpsJBossServer\PpsServerInstallScripts>GetDoneTimeByUID.bat
DONE_TIME=2017-07-18 13:57:33.818, ErrorLevel=0
Spezielle Stillstandszeiten abfragen:
- Stillstandszeiten mit folgenden Daten:
- Maschinen im Fehlerfall
- Sonstige Stillstände
- Gesamtlaufzeit
- Maschinen mit SKR-ID1530603103und1530627696
- Zeitraum2018-08-26 12:00bis2018-09-01 12:00
Diese Informationen lassen sich über eine individualisierte Stopp-Statistik ermitteln.
Mit Erzeugen einer Secondary DB und Auslösen eines individualisierten Reports.
Testweise geht das mit dem pgAdmin Tool. In diesem Beispiel werden statische Tabellen verwendet, die nicht automatisch gelöscht werden. Es wird die Tabelle mydb verwendet, die nach Testabschluss im Schema report_01 wieder gelöscht werden sollte.
Vorteil dieser Methode ist, die 2 Selects können in unterschiedliche SQL-Fenster eingegeben und die erzeugten Tabellen können im report_01 Schema eingesehen werden.
- 79
-
Secondary DB tables erzeugen.
SELECT * FROM skrpps_02.skr_create_secundary_db_tables_ex('report_01'::text ,'mydb'::text,'eUnlogged'::skrpps_02.e_sec_tabletype ,'skr'::text,ARRAY[1457359086, 1457359088],'2018-08-26 12:00'::timestamp,'2018-09-01 12:00'::timestamp,'2000','2:00:00'::interval); - 80
- Individuelle Stopp-Statistik generieren.
- Mit Rechenoperationen Spalten addieren oder subtrahieren, um das gewünschte Ergebnis zu erhalten.
- Zudem erhalten die neuen Ergebnisspalten eigene Namen (ERROR_STOP_DURATIONundOTHER_STOP_DURATION).
- Die Tabelle wird aufsteigend über die erste Spalte (Name der Maschine) sortiert.SELECT skrpps_02.skr_mcid2mcname( "AGG_MC_ID",'skr') AS "AGG_MC_NAME"
, "AGG_MC_ID",
("STOP_DURATION" - "ENGAGING_DURATION" - "PIECE_COUNTER_ZERO_DURATION" - "PROGRAMMING_DURATION" - "OFF_DURATION" - "BOOT_DURATION" - "NO_DATA_DURATION" - "MCSTATE_UNKNOWN_DURATION"
) AS "ERROR_STOP_DURATION",
("ENGAGING_DURATION" + "PIECE_COUNTER_ZERO_DURATION" + "PROGRAMMING_DURATION" + "OFF_DURATION" + "BOOT_DURATION" + "NO_DATA_DURATION" + "MCSTATE_UNKNOWN_DURATION") AS "OTHER_STOP_DURATION",
"RUN_DURATION"
FROM skrpps_02.eval_stop_statistic
(
'report_01' -- __sSchema text
,'mydb' -- _sTable_Prefix text
,Array['AGG_MC_ID'] -- _aSortorder text[]
,true -- _bGroupByMachine boolean
,false -- _bGroupByShift boolean
,false -- _bGroupByUserName boolean
,false -- _bGroupByPattern boolean
,false -- _bGroupBySeq boolean
,false -- _bGroupByTicketUid boolean
,false -- _bGroupByTicketProductionId boolean
,false -- _bGroupByTicketProductionSub1Id boolean
,false -- _bGroupByTicketProductionSub2Id boolean
,false -- _bGroupByTicketCustomerId boolean
,false -- _bGroupByTicketArticleId boolean
,NULL -- _aFilterShift integer[]
,NULL -- _aFilterUsername text[]
,NULL -- _aFilterPattern text[]
,NULL -- _aFilterSeq text[]
,NULL -- _aFilterTicketUid bigint[]
,NULL -- _aFilterTicketProductionId text[]
,NULL -- _aFilterTicketProductionsub1Id text[]
,NULL -- _aFilterTicketProductionsub2Id text[]
,NULL -- _aFilterTicketCustomerId text[]
,NULL -- _aFilterTicketArticleid text[]
,NULL -- _aFilterUserState Smallint[]
,NULL -- _aFilterSintralState Smallint[]
) where "OVERALL_DURATION" <> "NO_DATA_DURATION" order by 1 asc : Mit dem mitgelieferten Excel-Programm (StollReportFromSkrToExcel.xlsb) können Sie die Basisfiltereinstellungen einfach konfigurieren und die Select-Abfrage kopieren.
: Mit dem mitgelieferten Excel-Programm (StollReportFromSkrToExcel.xlsb) können Sie die Basisfiltereinstellungen einfach konfigurieren und die Select-Abfrage kopieren.
So greifen Sie über ODBC auf die Datenbank zu
- Beispielergebnis der Abfrage

So führen Sie einen Auftrag ohne eine XML-Datei zu erzeugen direkt der Datenbank zu
Anstatt die Auftragsdaten in eine XML-Datei zu schreiben und diese in den D:\ERP\Input Ordner zu legen, können Sie den Auftrag direkt über eine Datenbankverbindung zur pps Datenbank in die ticket_queue einfügen.
Der nachfolgende Insert fügt einen Auftrag mit minimalem Datensatz für die Auto-Produktion in die ticket_queue ein. Gedacht ist er zum Nachladen eines Jacquards bei einer Individualproduktion mit Losgröße 1. Andere Auftragsvarianten sind gleichermaßen möglich.
Über die Beispiel Excel-Datei D:\PPS\ODBC_Examples\Excel\StollPpsTicketExportViaODBC.xlsm, können Sie sich weitere Anwendungen erarbeiten.
Dazu ist eine ODBC-Verbindung zur pps- und nicht zur skr-Datenbank notwendig.
Die Strickzeit (estimated_order_duration) wird in Millisekunden übergeben.
20 min sind daher als 20*60*1000=1200000 einzutragen.
INSERT INTO "ticket_queue" (
ticket_number,
ticket_type,
pattern_subdirectory,
pattern_file_name,
total_num_of_executions,
estimated_order_duration,
custom_xml, machine_list_xml,
order_description,
pattern_preload_condition_xml
)
Values (
'145609_bandage_2154879',
'AUTO_PRODUCTION',
'production\Spring2019',
'CMSADF-3 KW.bandage_2154879.zip',
1,
1200000,
'<STOLL:CUSTOM xmlns="http://schemas.custom.com/ticketing/ticket/v0.3" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://schemas.custom.com/ticketing/ticket/v0.3 CustomTicket.xsd"/>',
'<STOLL:MACHINE_LIST>
<STOLL:MACHINE Name="312_ADF-3KW" BoIgnore="1" Pieces="1"/>
</STOLL:MACHINE_LIST>',
'Ticket created by Sapas',
'<STOLL:PATTERN_PRELOAD_CONDITION>
<STOLL:ERASE_ALL State="false"/>
<STOLL:ERASE_ALL_YARNCARRIERPOS State="false"/>
<STOLL:ERASE_ALL_SEQYARNCARRIERPOS State="false"/>
<STOLL:LOAD_PAT_CONTAINER_COMP SIN="false" JAC="true" SET="false"/>
</STOLL:PATTERN_PRELOAD_CONDITION>'
)
Produzierte Teile in der noch laufenden, ticketbasierten Produktion ermitteln
Sie möchten ermitteln, wie viele Teile der laufenden Produktion an den Maschinen schon produziert wurden?
Mit nachfolgender Abfrage der PPS-Datenbank, erhalten Sie Auskunft über die Produktion:
- wie viele Teile
- von wie vielen Maschinen
- auf welchen Maschinen
- welches Ticket
- welcher Auftrag
- wie viele nicht abgeschlossene Tickets
SELECT d.name AS device_name, executionsdone, numberofexecutions, t.name AS ticket_name, ordernumber AS order_name, patternfilename FROM Ticket t JOIN Device d on device_id=d.id JOIN Orders o ON o.id = t.order_id WHERE o.type in ('GENERAL','AUTO_PRODUCTION', 'GUIDED_PRODUCTION') and t.state ='IN_PROGRESS' order by order_name
Produzierte Sequenzen pro Tag und Maschine ermitteln:
- Wird z.B. ein Pullover über eine Sequenz gestrickt und man will ermitteln, wie viele Pullover am Tag pro Maschine über einen bestimmten Zeitraum hergestellt wurden, so lässt sich das über den EventList Report ermitteln:
- Maschinen mit SKR-ID 1706536365, 1710405527, 1710409205, 1711546385, 1706535846, 1711443250, 1607342198, 1704803012, 1718697144, 1718692632
- Zeitraum2024-04-09 00:00bis2024-08-01 00:00Nach Erzeugen einer Secondary DB kann der EventList Report verwendet werden. Dabei wird der Event Filter für Sequence number increased (1,4) verwendet.
Testweise geht das mit dem pgAdmin Tool. Damit die 2 Selects in der gleichen Session laufen, müssen die Abfragen in einem SQL-Fenster eingegeben werden.
- 1
-
Secondary DB tables erzeugen
SELECT * FROM skrpps_02.skr_create_secundary_db_tables_ex(''::text ,'mydb'::text,'eUnloggedTemp'::skrpps_02.e_sec_tabletype ,'skr'::text, ARRAY[1706536365, 1710405527, 1710409205, 1711546385, 1706535846, 1711443250, 1607342198, 1704803012, 1718697144, 1718692632],'2024-04-09 00:00'::timestamp,'2024-08-01 00:00'::timestamp,'2000','2:00:00'::interval); - 2
- Individuellen EventList-Report generieren.
- Tageweise wird nach Maschinen und Sequenzen gruppiert und die Anzahl der Sequenzen gezählt.
- Die Ergebnistabelle gibt Maschinenname, Sequenzname (kann Mustername zusätzlich enthalten), Tag und Anzahl der Sequenzen aus.: Die Anzahl der Sequenzen wird nur dann stimmen, wenn die Produktion regulär abgelaufen ist.
Mit dieser Abfrage können keine übersprungenen oder abgebrochenen Sequenzelemente berücksichtigt werden.Select skrpps_02.skr_mcid2mcname( "MC_ID",'skr'::cstring) AS "MC_NAME",
"SEQ_PATTERN_NAME",
DATE_TRUNC('day', "TIME_STAMP") AS "DAY",
COUNT(*) "NumbOfSequences"
from
skrpps_02.eval_event_list(
'' -- __sSchema text
,'mydb' -- _sTable_Prefix text
,'EN' -- _sLang text
,1 -- _iStartId bigint
,10000 -- _iLimit int
,ARRAY[[1,4]]::smallint[][2] -- _aFilterEvents smallint[][2]
,NULL -- _aFilterShift integer[]
,NULL -- _aFilterUsername text[]
,NULL -- _aFilterPattern text[]
,NULL -- _aFilterSeq text[]
,NULL -- _aFilterTicketUid bigint[]
,NULL -- _aFilterTicketProductionId text[]
,NULL -- _aFilterTicketProductionsub1Id text[]
,NULL -- _aFilterTicketProductionsub2Id text[]
,NULL -- _aFilterTicketCustomerId text[]
,NULL -- _aFilterTicketArticleid text[]
,NULL -- _aFilterUserState Smallint[]
,NULL -- _aFilterSintralState Smallint[]
)
GROUP BY skrpps_02.skr_mcid2mcname("MC_ID", 'skr'::cstring),
"SEQ_PATTERN_NAME",
DATE_TRUNC('day', "TIME_STAMP")
ORDER BY "DAY";: Mit dem mitgelieferten Excel-Programm (StollReportFromSkrToExcel.xlsb) können Sie die Basisfiltereinstellungen einfach konfigurieren und die Select-Abfrage kopieren.
So greifen Sie über ODBC auf die Datenbank zu
- Beispielergebnis der Abfrage mit dem pgAdmin Tool
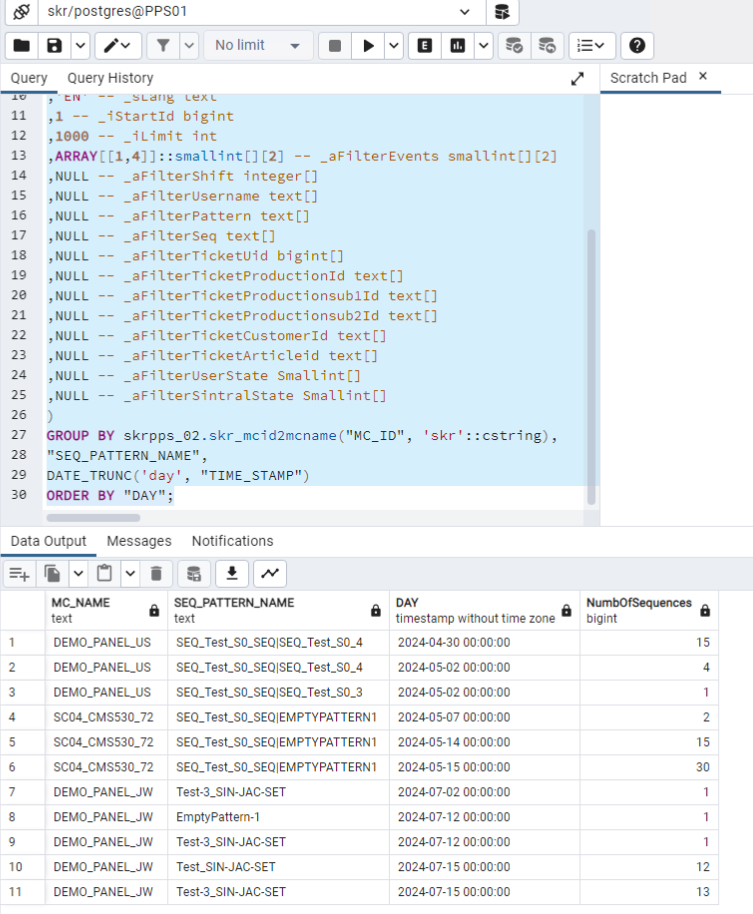
Sie möchten die Zwischentabellen und Auswertung in einem Aufruf erzeugen
In diesem Beispiel wird die Hilfstabelle zusammen mit der Event Liste erzeugt.
Beachten Sie, dass im Fehlerfall die Analyse erschwert wird. Die erste Spalte skr_create_secundary_db_tables_ex sollte durchgängig den Wert 0 haben, damit sichergestellt ist, dass für alle Maschinen die Hilfstabelle erzeugt werden konnten.
Im Beispiel wird, nach der Erzeugung der Hilfstabellen, der Event List Report ausgeführt.
Sie können diesen Teil des SELECT durch einen anderen Report ersetzen, der auf den Hilfstabellen basiert.
SELECT
skrpps_02.skr_create_secundary_db_tables_ex
(''::text ,'mydb'::text,'eUnloggedTemp'::skrpps_02.e_sec_tabletype ,'skr'::text, ARRAY[1706536365, 1710405527, 1710409205, 1711546385, 1706535846, 1711443250, 1607342198, 1704803012, 1718697144, 1718692632],'2024-04-09 00:00'::timestamp,'2028-08-01 00:00'::timestamp,'2000','2:00:00'::interval)
, skrpps_02.skr_mcid2mcname("MC_ID",'skr'::cstring) AS "MC_NAME"
skrpps_02.eval_event_list
,* from (
'' -- __sSchema text
,'mydb' -- _sTable_Prefix text
,'EN' -- _sLang text
,1 -- _iStartId bigint
,1000 -- _iLimit int
,NULL::smallint[][2] -- _aFilterEvents smallint[][2]
,NULL -- _aFilterShift integer[]
,NULL -- _aFilterUsername text[]
,NULL -- _aFilterPattern text[]
,NULL -- _aFilterSeq text[]
,NULL -- _aFilterTicketUid bigint[]
,NULL -- _aFilterTicketProductionId text[]
,NULL -- _aFilterTicketProductionsub1Id text[]
,NULL -- _aFilterTicketProductionsub2Id text[]
,NULL -- _aFilterTicketCustomerId text[]
,NULL -- _aFilterTicketArticleid text[]
,NULL -- _aFilterUserState Smallint[]
,NULL -- _aFilterSintralState Smallint[]
);
Den Report in eine CSV-Datei exportieren:
Angenommen, Sie möchten die Laufzeit einer Maschine an einem Tag ermitteln.
Die Stopp-Statistik gibt darüber in der Spalte RUN_DURATION Auskunft.
Mit dem Postgres-Befehl Copy können Sie die Ergebnistabelle in eine CSV-Datei exportieren.
- 1
- Die Secundary-DB für den gewünschten Tag und Maschine erstellen.
- 2
- Den benötigten Report erstellen.
- 3
- Für weitere Reports nach gleichem Schema vorgehen, sofern die Secundary-DB nötig ist.
Ansonsten können Sie die gewünschte Tabelle direkt abrufen.
Im pgAdmin4 Programm können Sie den Aufruf testen:SELECT * FROM skrpps_02.skr_create_secundary_db_tables_ex(
''::text ,'mydb'::text,
'eUnloggedTemp'::skrpps_02.e_sec_tabletype ,'skr'::text, ARRAY[1718692632],
'2024-06-25 00:00'::timestamp,
'2024-06-26 00:00'::timestamp,
'2000','2:00:00'::interval);
copy (
SELECT skrpps_02.skr_mcid2mcname("AGG_MC_ID",'skr') AS "AGG_MC_NAME"
, * FROM skrpps_02.eval_stop_statistic_ex
('' -- __sSchema text
,'mydb' -- _sTable_Prefix text
,NULL -- _aSortorder text[]
,false -- _bGroupByMachine boolean
,false -- _bGroupByShift boolean
,false -- _bGroupByUserName boolean
,false -- _bGroupByPattern boolean
,false -- _bGroupBySeq boolean
,false -- _bGroupByTicketUid boolean
,false -- _bGroupByTicketProductionId boolean
,false -- _bGroupByTicketProductionSub1Id boolean
,false -- _bGroupByTicketProductionSub2Id boolean
,false -- _bGroupByTicketCustomerId boolean
,false -- _bGroupByTicketArticleId boolean
,false -- _bGroupByDay boolean
,false -- _bGroupByWeek boolean
,false -- _bGroupByMonth boolean
,NULL -- _aFilterShift integer[]
,NULL -- _aFilterUsername text[]
,NULL -- _aFilterPattern text[]
,NULL -- _aFilterSeq text[]
,NULL -- _aFilterTicketUid bigint[]
,NULL -- _aFilterTicketProductionId text[]
,NULL -- _aFilterTicketProductionsub1Id text[]
,NULL -- _aFilterTicketProductionsub2Id text[]
,NULL -- _aFilterTicketCustomerId text[]
,NULL -- _aFilterTicketArticleid text[]
,NULL -- _aFilterUserState Smallint[]
,NULL -- _aFilterSintralState Smallint[]
) where "OVERALL_DURATION" <> "NO_DATA_DURATION"
) TO 'D:\PPS\Temp\StopStatistic.csv' WITH (FORMAT CSV, HEADER TRUE, DELIMITER E'\t') ;
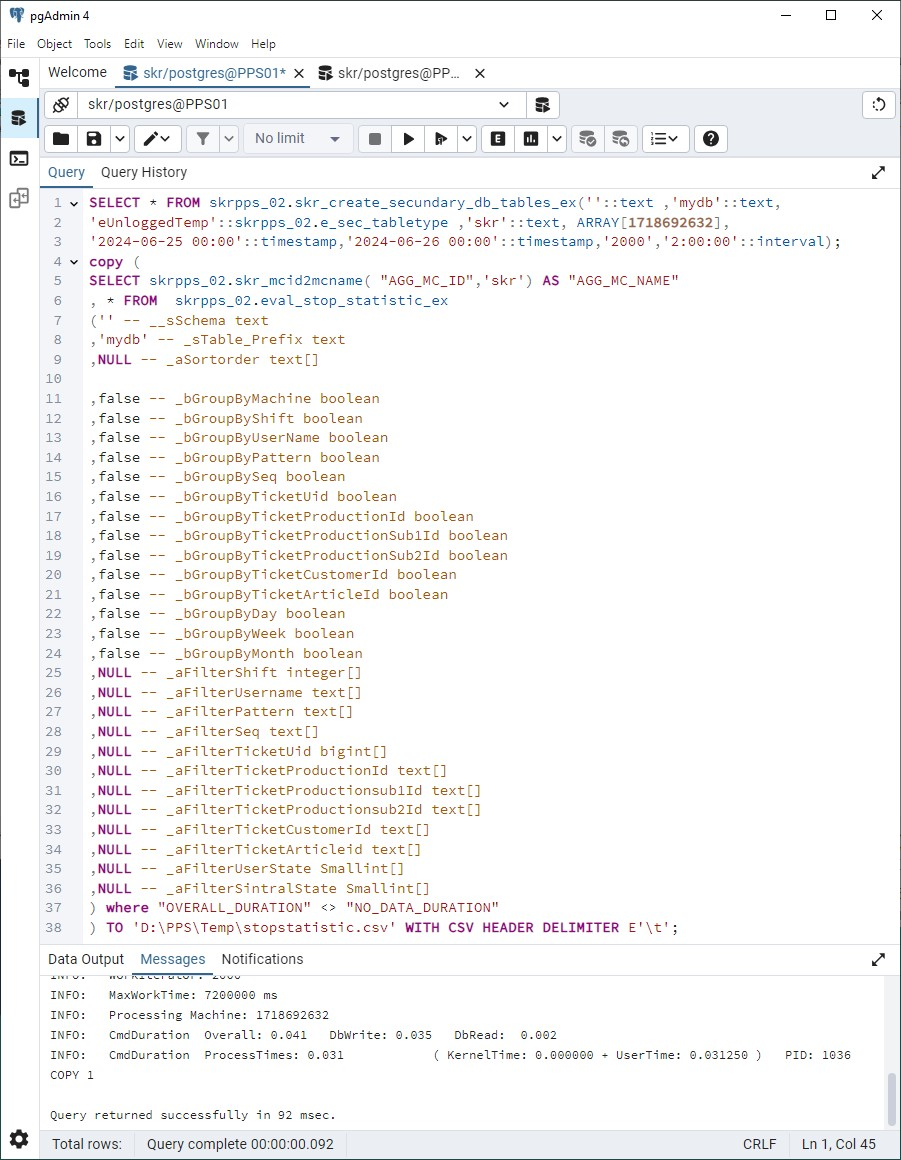
Das Verzeichnis, in dem die CSV-Datei abgelegt wird, muss Schreibberechtigung für den _Skr2DbUser haben.
Den Aufruf können Sie in einen Batch und in eine *.sql Datei aufteilen.
- 1
- Den ersten Text in eine Batchdatei
StopStatistic.batkopieren. - 2
- Den zweiten Text in die
export_report.sqlDatei - 3
- Zeitraum, Maschinen-IDs und das Zielverzeichnis anpassen.
- Die Spalten werden per Tab separiert und das Ergebnis in eine CSV-Datei
'D:\PPS\Temp\StopStatistic.csv'geschrieben. - Per Datenimport können Sie die Datei in Excel laden:
@echo off
REM File StopStatistic.bat
SET "PGPATH=C:\Program Files\Stoll\skr3_15\PostgreSql\15.12-1\bin"
SET PGPASSWORD=skrfrontend
SET SQL_FILE="D:\PPS\Temp\export_report.sql"
SET ERROR_LOG="D:\PPS\Temp\psql_error.log"
del %ERROR_LOG% 2>NUL
"%PGPATH%\psql" -U skrfrontend -d skr -h localhost -f %SQL_FILE% > %ERROR_LOG% 2>&1
if %ERRORLEVEL% NEQ 0 (
echo Error executing PostgreSQL commands!
echo Check %ERROR_LOG% for details.
type %ERROR_LOG%
pause
) else (
echo CSV export completed successfully.
echo Check %ERROR_LOG% for any warnings or notices.
type %ERROR_LOG%
)
-- File export_report.sql
\set ON_ERROR_STOP on
SELECT skrpps_02.skr_create_secundary_db_tables_ex (
''::text,
'mydb'::text,
'eUnloggedTemp'::skrpps_02.e_sec_tabletype,
'skr'::text,
ARRAY[1718692632],
'2024-06-25 00:00'::timestamp,
'2024-06-26 00:00'::timestamp,
'2000',
'2:00:00'::interval
);
\copy (Select skrpps_02.skr_mcid2mcname ( "AGG_MC_ID",'skr') AS "AGG_MC_NAME", * from skrpps_02.eval_stop_statistic_ex ('' , 'mydb', NULL, true, false, false, false, false, false, false, false, false, false, false, false, false, false, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL) WHERE "OVERALL_DURATION" <> "NO_DATA_DURATION") TO 'D:\PPS\Temp\StopStatistic.csv' WITH (FORMAT CSV, HEADER TRUE, DELIMITER E'\t') ;