Evaluating the Pattern Statistics
The pattern statistics, essentially, are a statistic summary of the production report.
The grouping can be made very flexibly by different columns (also combined)
Therefore, most of the columns of the return table contain arrays.
In case of unfavorable groupings over a larger evaluation period, these arrays can become very big, which then affects unfavorably the performance of the evaluations.
Example: Evaluation over one year
The grouping is made only by machines. (Not combined with grouping by pattern or ticket)
The result column AGG_PATTERN_NAME than contains an array with all pattern names that were produced in this year.
Call-up parameters:
Note regarding the filters:
Like with the production report all the filters are implemented as "weak" filters
Overview of Reports
|
Parameter | Type | Description |
|---|---|---|
__sSchema | text | Schema of the secondary database tables. |
_sTable_Prefix | text, | Prefix of the secondary database tables |
_aSortorder | text[] | Sorting (Array of column names) Example: ARRAY['MC_SORT_ID','START_TIME'] |
_bGroupByMachine | boolean | Group by machine |
_bGroupByShift | boolean | Group by shift |
_bGroupByUserName | boolean | Group by user (at the machine) |
_bGroupByPattern | boolean | Group by pattern |
_bGroupBySeq | boolean | Group by sequence |
_bGroupByTicketUid | boolean | Group by ticket (PPS UID) |
_bGroupByTicketProductionId | boolean | Group by ticket production ID |
_bGroupByTicketProductionSub1Id | boolean | Group by ticket production sub ID 1 |
_bGroupByTicketProductionSub2Id | boolean | Group by ticket production sub ID 2 |
_bGroupByTicketCustomerId | boolean | Group by ticket customer ID |
_bGroupByTicketArticleId | boolean | Group by ticket article ID |
_aFilterShift | integer[] | Filter by shift(s) Example: |
_aFilterUsername | text[] | Filter by users (knitter) Example: ARRAY[‚User_1,'User_3'] |
_aFilterPattern | text[] | Filter by sequences Example: ARRAY['S-kUuG01','P-Sjo9v3'] |
_aFilterSeq | text[] | Filter by sequences Example: ARRAY['SEQ-WNJhP3','SEQ-wMWzx2'] |
_aFilterTicketUid | bigint[][] | Filter by internal ticket UID Example: ARRAY[3374994314,3738720541] |
_aFilterTicketProductionId | text[] | Filter by ID production ticket Example: ARRAY['2E0Hl4-H8T803-cId-8','2E0Hl4-H8T803-cId-8'] |
_aFilterTicketProductionsub1Id | text[] | Filter by ticket production sub1ID Example: ARRAY['SubId_2','SubId_21'] |
_aFilterTicketProductionsub2Id | text[] | Filter by ticket production sub2ID Example: ARRAY['-'] |
_aFilterTicketCustomerId | text[] | Filter by ticket customer ID Example: ARRAY['cId-2','cId-4'] |
_aFilterTicketArticleid | text[] | Filter by ticket article ID Example: ARRAY['H8T803'] |
_aFilterUserState | Smallint[] | Filter by user state Example: ARRAY[4,3] |
_aFilterSintralState | Smallint[] | Filter by Sintral state Example: ARRAY[4,3] |
_xFilterMinDuration | interval | Filter out the fabric pieces that were active less than x seconds. |
_bFilterUseOnlyNettoTime | boolean | Include only net times. ( == Machine has the productive flag == Time from loading pattern until Stop by piece counter is 0 ) |
_bFilterUseOnlyProductiveTicketTime | boolean | If == true, the times with service tickets or of producing without ticket will be filtered out. |
Return Table
 Notes:
Notes:
- The return table contains additional "debug" columns whose names are between square brackets.
Example: [MIN_UID] - Most of the columns return arrays as return value.
- Depending on the used grouping, these, often, have only one entry.
|
Column | Type | Content |
|---|---|---|
MC_ID | integer | SKR machine ID |
MC_SORT_ID | smallint | For alphabetical sorting by machine name |
AGG_SEQ_NAME | text[] | Sequence name (n) |
AGG_PATTERN_NAME | text[] | Pattern name (n) |
START_TIME | timestamp without time zone | Start time |
END_TIME | timestamp without time zone | End time |
AGG_SHIFT_STATES | smallint[] | Active shifts |
AGG_USER_STATES | smallint[] | Active user states during the processing of the piece or ticket |
AGG_SINTRAL_STATES | smallint[] | Sintral states during the processing of the piece or ticket |
AGG_USER_NAME | smallint[] | Active users during the processing of the piece or ticket |
AGG_TICKET_DATA | text[] | Ticket Data |
KNIT_COUNT | integer | Number of complete fabric pieces (not canceled) |
BREAK_COUNT | integer | Number of canceled fabric pieces |
SUM_BREAK_DURATION | interval | Time that was used for canceled pieces / tickets (Probably, the column only makes sense, if it was grouped by pattern) |
AVG_DURATION | interval | Average time per fabric piece
|
MIN_DURATION | interval | Minimum time per fabric piece with standstill times canceled pieces are ignored |
MAX_DURATION | interval | Maximum time per fabric piece with standstill times, canceled pieces are ignored |
SUM_DURATION | interval | Time in total
|
AVG_KNIT_DURATION | interval | Average time per fabric piece
|
MIN_KNIT_DURATION | interval | Minimum time per fabric piece
|
MAX_KNIT_DURATION | interval | Maximum time per fabric piece
|
SUM_KNIT_DURATION | interval | Time in total
|
[MIN_UID] | bigint | Debug info: Start time UID in <prefix>_collected_filter_rows |
[MAX_UID] | bigint | Debug info: End time UID in <prefix>_collected_filter_rows |
[AGG_TICKET_UID] | bigint[] | Debug info: Active ticket UID’s |
[AGG_TICKET_CUSTOMER_ID] | text[] | Debug info: Active ticket CUSTOMER ID‘s |
[AGG_TICKET_ARTICLE_ID] | text[] | Debug info: Active ticket ARTICLE ID‘s |
[AGG_TICKET_PRODUCTION_ID] | text[] | Debug info: Active ticket PRODUCTION_ID‘s |
[AGG_TICKET_PRODUCTION_SUB1_ID] | text[] | Debug info: Active ticket PRODUCTION_SUB1_ID‘s |
[AGG_TICKET_PRODUCTION_SUB2_ID] | text[] | Debug info: Active ticket PRODUCTION_SUB2_ID‘s |
Code example „sample_pattern_statistik.sql“
Important:
It is assumed that the evaluation auxiliary tables report_01.sample_xxxxxxxx are already generated.
Generating evaluation auxiliary tables (cursor run - UDF)
For a productive system, enter an empty field ‘‘ instead of report_01, schema. But it must be identical to that which was specified when generating the auxiliary tables.
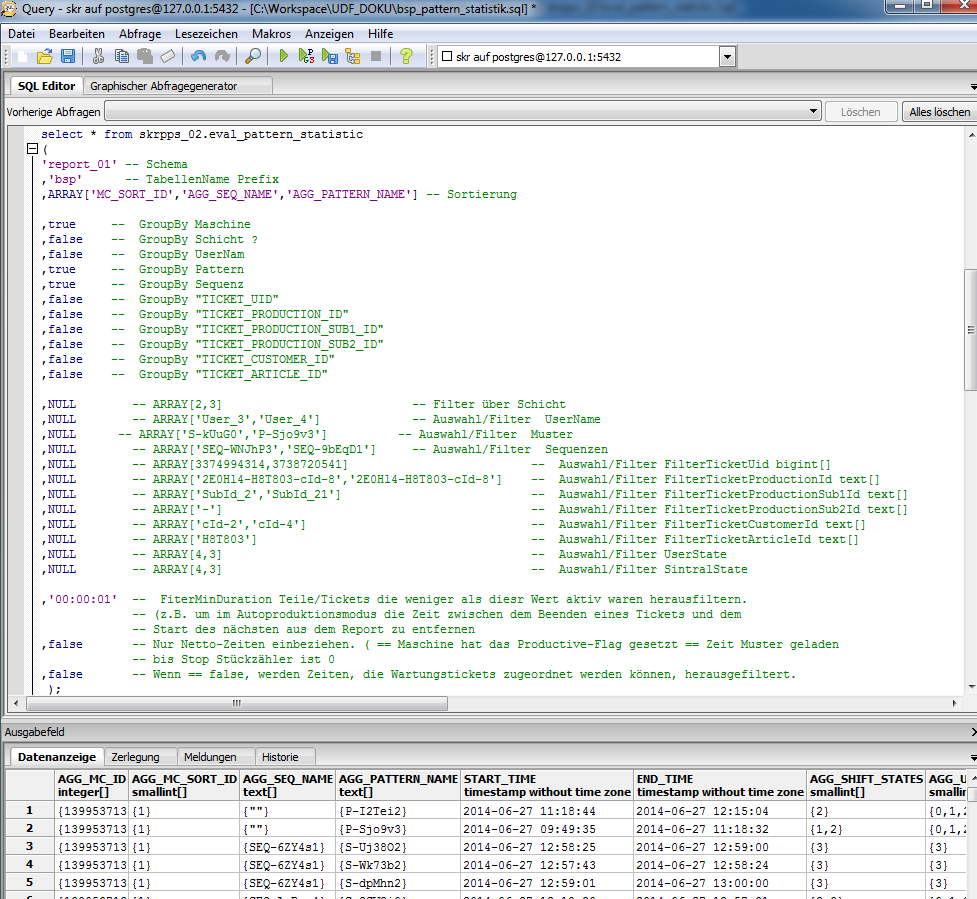
select * from skrpps_02.eval_pattern_statistic
(
'report_01' -- Schema
,'sample' – Table Name Prefix
,ARRAY['AGG_MC_SORT_ID','AGG_SEQ_NAME','AGG_PATTERN_NAME'] – Sorting
,true -- GroupBy Machine
,false -- GroupBy Shift?
,false -- GroupBy UserName
,true -- GroupBy Pattern
,true -- GroupBy Sequence
,false -- GroupBy "TICKET_UID"
,false -- GroupBy "TICKET_PRODUCTION_ID"
,false -- GroupBy "TICKET_PRODUCTION_SUB1_ID"
,false -- GroupBy "TICKET_PRODUCTION_SUB2_ID"
,false -- GroupBy "TICKET_CUSTOMER_ID"
,false -- GroupBy "TICKET_ARTICLE_ID"
,NULL -- ARRAY[2,3] -- Filter by shift
,NULL -- ARRAY['User_3','User_4'] -- Selection/Filter UserName
,NULL -- ARRAY['S-kUuG0','P-Sjo9v3'] -- Selection/Filter Pattern
,NULL -- ARRAY['SEQ-WNJhP3','SEQ-9bEqD1'] -- Selection/Filter Sequences
,NULL -- ARRAY[3374994314,3738720541] -- Selection/Filter FilterTicketUid bigint[]
,NULL -- ARRAY['2E0Hl4-H8T803-cId-8','2E0Hl4-H8T803-cId-8'] -- Selection/Filter FilterTicketProductionId text[]
,NULL -- ARRAY['SubId_2','SubId_21'] -- Selection/Filter FilterTicketProductionSub1Id text[]
,NULL -- ARRAY['-'] -- Selection/Filter FilterTicketProductionSub2Id text[]
,NULL -- ARRAY['cId-2','cId-4'] -- Selection/Filter FilterTicketCustomerId text[]
,NULL -- ARRAY['H8T803'] -- Selection/Filter FilterTicketArticleId text[]
,NULL -- ARRAY[4,3] -- Selection/Filter UserState
,NULL -- ARRAY[4,3] -- Selection/Filter SintralState
,'00:00:01' -- FilterMinDuration‚ Filter-out fabric pieces or tickets with a duration shorter than the specified value.
-- (e.g. in order to keep times after ending a ticket and before starting the next out of the report in case of the Auto Production Mode)
,false – Evaluate net times only. ( == Machine has set the Productive flag == Time from pattern loaded state to Piece Counter is zero
,false – If == false, all times allocated to service tickets will be filtered-out.
);