评估花型统计
花型统计本质上是生产报表的统计摘要。
可以非常灵活地通过不同列进行分组(也可以合并)
因此,返回表的大部分列包含数组。
如果不合适的分组发生在一个较大的评估区段,这些数组可能会变得非常庞大,会对评估的效果造成不利影响。
示例:年度评估
只按机器分组。(不与按花型分组或按工票分组合并)
结果列AGG_PATTERN_NAME包含了今年生产的所有花型名称的数组。
调用参数:
有关筛选器的注释:
像生产报表一样,所有的筛选器都是“弱”筛选器
报表概览
|
参数 | 型号 | 描述 |
|---|---|---|
__sSchema | text | 辅助数据库表的 schema。 |
_sTable_Prefix | text, | 辅助数据库表的前缀 |
_aSortorder | text[] | 排序(列标题数组) 示例: ARRAY['MC_SORT_ID','START_TIME'] |
_bGroupByMachine | boolean | 按机器分组 |
_bGroupByShift | boolean | 按班次分组 |
_bGroupByUserName | boolean | 按用户分组(在机器上) |
_bGroupByPattern | boolean | 按花型分组 |
_bGroupBySeq | boolean | 按顺序分组 |
_bGroupByTicketUid | boolean | 按工票分组(PPSUID) |
_bGroupByTicketProductionId | boolean | 按工票生产 ID 分组 |
_bGroupByTicketProductionSub1Id | boolean | 按工票生产子 ID1 分组 |
_bGroupByTicketProductionSub2Id | boolean | 按工票生产子 ID2 分组 |
_bGroupByTicketCustomerId | boolean | 按工票客户 ID 分组 |
_bGroupByTicketArticleId | boolean | 按工票货品 ID 分组 |
_aFilterShift | integer[] | 按班次筛选 示例: |
_aFilterUsername | text[] | 按用户筛选(挡车工) 示例: ARRAY[‚User_1,'User_3'] |
_aFilterPattern | text[] | 按顺序筛选 示例: ARRAY['S-kUuG01','P-Sjo9v3'] |
_aFilterSeq | text[] | 按顺序筛选 示例: ARRAY['SEQ-WNJhP3','SEQ-wMWzx2'] |
_aFilterTicketUid | bigint[][] | 按内部工票UID 筛选 示例: ARRAY[3374994314,3738720541] |
_aFilterTicketProductionId | text[] | 按生产工票ID筛选 示例: ARRAY['2E0Hl4-H8T803-cId-8','2E0Hl4-H8T803-cId-8'] |
_aFilterTicketProductionsub1Id | text[] | 按工票生产sub1D筛选 示例: ARRAY['SubId_2','SubId_21'] |
_aFilterTicketProductionsub2Id | text[] | 按工票生产sub2D筛选 示例: ARRAY['-'] |
_aFilterTicketCustomerId | text[] | 按工票客户 ID 筛选 示例: ARRAY['cId-2','cId-4'] |
_aFilterTicketArticleid | text[] | 按工票货品 ID 筛选 示例: ARRAY['H8T803'] |
_aFilterUserState | Smallint[] | 按用户状态筛选 示例: ARRAY[4,3] |
_aFilterSintralState | Smallint[] | 按Sintral状态筛选 示例: ARRAY[4,3] |
_xFilterMinDuration | interval | 筛选掉活动时间小于x秒的织片。 |
_bFilterUseOnlyNettoTime | boolean | 只包括净时间。( == 机器具有生产标志 == 从导入花型直至片数计数器为 0 时停机的时间 ) |
_bFilterUseOnlyProductiveTicketTime | boolean | 如果== 真,服务工票的时间或无工票生产的时间将被筛选掉。 |
返回表
 注意:
注意:
- 返回表包含附加“调试”列,其名称在方括号之间。
示例: [MIN_UID] - 大部分列返回数组作为返回值。
- 根据所使用的分组,通常情况下,只有一个条目。
|
列 | 型号 | 内容 |
|---|---|---|
MC_ID | integer | SKR 机器 ID |
MC_SORT_ID | smallint | 按机器名称按字母顺序排序 |
AGG_SEQ_NAME | text[] | 顺序名称 (n) |
AGG_PATTERN_NAME | text[] | 花型名称 (n) |
START_TIME | timestamp without time zone | 开始时间 |
END_TIME | timestamp without time zone | 结束时间 |
AGG_SHIFT_STATES | smallint[] | 活动班次 |
AGG_USER_STATES | smallint[] | 织片或工票处理过程中活动的用户状态 |
AGG_SINTRAL_STATES | smallint[] | 织片或工票处理过程中的Sintral状态 |
AGG_USER_NAME | smallint[] | 织片或工票处理过程中处于活动状态的用户 |
AGG_TICKET_DATA | text[] | 工票数据 |
KNIT_COUNT | integer | 完成织片数量(未取消) |
BREAK_COUNT | integer | 取消织片数量 |
SUM_BREAK_DURATION | interval | 用于取消的织片/工票的时间 (可能的情况是,只有当列按花型分组时才有意义) |
AVG_DURATION | interval | 每个织片的平均时间
|
MIN_DURATION | interval | 每个织片的最短时间 包括停机时间 忽略已取消的织片 |
MAX_DURATION | interval | 包括停机时间的每个织片最长时间,忽略已取消的织片 |
SUM_DURATION | interval | 总时间
|
AVG_KNIT_DURATION | interval | 每个织片的平均时间
|
MIN_KNIT_DURATION | interval | 每个织片的最短时间
|
MAX_KNIT_DURATION | interval | 每个织片的最长时间
|
SUM_KNIT_DURATION | interval | 总时间
|
[MIN_UID] | bigint | 调试信息:<prefix>_collected_filter_rows 中开始时间 UID |
[MAX_UID] | bigint | 调试信息:<prefix>_collected_filter_rows 中结束时间UID |
[AGG_TICKET_UID] | bigint[] | 调试信息:活动工票UID’s |
[AGG_TICKET_CUSTOMER_ID] | text[] | 调试信息:活动工票CUSTOMER ID‘s |
[AGG_TICKET_ARTICLE_ID] | text[] | 调试信息:活动工票ARTICLE ID‘s |
[AGG_TICKET_PRODUCTION_ID] | text[] | 调试信息:活动工票PRODUCTION_ID‘s |
[AGG_TICKET_PRODUCTION_SUB1_ID] | text[] | 调试信息:活动工票PRODUCTION_SUB1_ID‘s |
[AGG_TICKET_PRODUCTION_SUB2_ID] | text[] | 调试信息:活动工票PRODUCTION_SUB2_ID‘s |
代码示例„sample_pattern_statistik.sql“
重要点:
假设评估辅表report_01.sample_xxxxxxxx已经生成。
创建评估辅表(光标运行- UDF)
为高效工作,输入一个空的字段‘‘而不是report_01,架构。但必须与创建辅表时指定的内容相同。
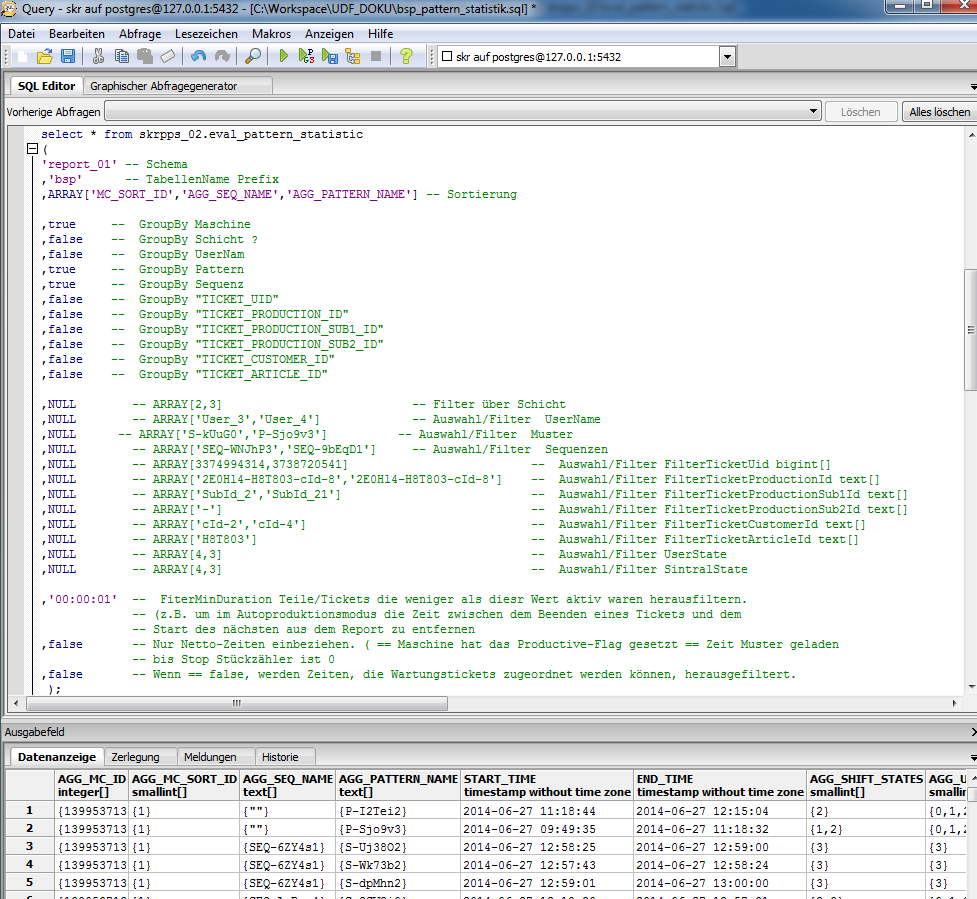
select * from skrpps_02.eval_pattern_statistic
(
'report_01' -- Schema
,'sample' – Table Name Prefix
,ARRAY['AGG_MC_SORT_ID','AGG_SEQ_NAME','AGG_PATTERN_NAME'] – Sorting
,true -- GroupBy Machine
,false -- GroupBy Shift?
,false -- GroupBy UserName
,true -- GroupBy Pattern
,true -- GroupBy Sequence
,false -- GroupBy "TICKET_UID"
,false -- GroupBy "TICKET_PRODUCTION_ID"
,false -- GroupBy "TICKET_PRODUCTION_SUB1_ID"
,false -- GroupBy "TICKET_PRODUCTION_SUB2_ID"
,false -- GroupBy "TICKET_CUSTOMER_ID"
,false -- GroupBy "TICKET_ARTICLE_ID"
,NULL -- ARRAY[2,3] -- Filter by shift
,NULL -- ARRAY['User_3','User_4'] -- Selection/Filter UserName
,NULL -- ARRAY['S-kUuG0','P-Sjo9v3'] -- Selection/Filter Pattern
,NULL -- ARRAY['SEQ-WNJhP3','SEQ-9bEqD1'] -- Selection/Filter Sequences
,NULL -- ARRAY[3374994314,3738720541] -- Selection/Filter FilterTicketUid bigint[]
,NULL -- ARRAY['2E0Hl4-H8T803-cId-8','2E0Hl4-H8T803-cId-8'] -- Selection/Filter FilterTicketProductionId text[]
,NULL -- ARRAY['SubId_2','SubId_21'] -- Selection/Filter FilterTicketProductionSub1Id text[]
,NULL -- ARRAY['-'] -- Selection/Filter FilterTicketProductionSub2Id text[]
,NULL -- ARRAY['cId-2','cId-4'] -- Selection/Filter FilterTicketCustomerId text[]
,NULL -- ARRAY['H8T803'] -- Selection/Filter FilterTicketArticleId text[]
,NULL -- ARRAY[4,3] -- Selection/Filter UserState
,NULL -- ARRAY[4,3] -- Selection/Filter SintralState
,'00:00:01' -- FilterMinDuration‚ Filter-out fabric pieces or tickets with a duration shorter than the specified value.
-- (e.g. in order to keep times after ending a ticket and before starting the next out of the report in case of the Auto Production Mode)
,false – Evaluate net times only. ( == Machine has set the Productive flag == Time from pattern loaded state to Piece Counter is zero
,false – If == false, all times allocated to service tickets will be filtered-out.
);